Federated Learning Architectures: Boosting Healthcare AI Privacy

Federated learning architectures offer a robust solution to enhance data privacy in U.S. healthcare AI research by allowing models to train on decentralized datasets without direct data sharing, significantly reducing privacy risks by an estimated 20%.
In the rapidly evolving landscape of artificial intelligence, particularly within sensitive sectors like U.S. healthcare, the imperative to safeguard patient data is paramount. The question isn’t just about developing powerful AI models, but how to do so without compromising privacy. This article delves into federated learning healthcare privacy, exploring how various architectural designs are revolutionizing AI research by substantially mitigating data privacy risks, potentially by as much as 20% in U.S. healthcare applications.
Understanding Federated Learning in Healthcare
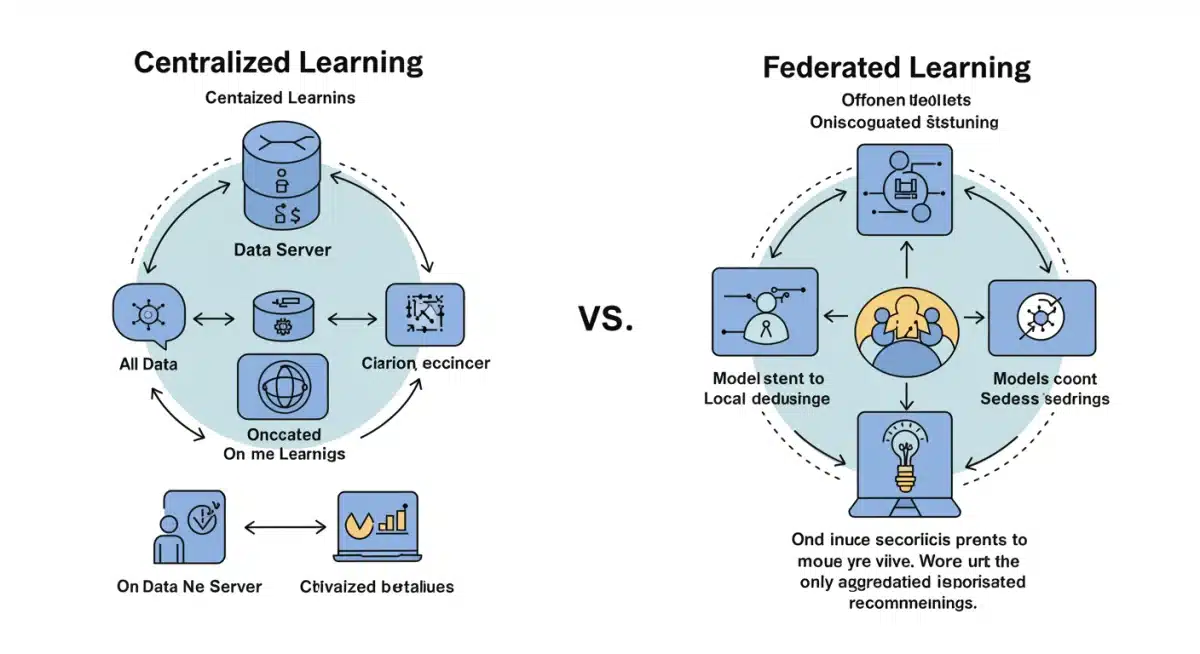
Federated learning represents a paradigm shift in how AI models are trained, moving away from the traditional centralized approach where all data is pooled in one location. Instead, it allows for collaborative model training across multiple decentralized datasets, where the data remains local to its source. This distributed approach is particularly potent in healthcare, where privacy regulations like HIPAA strictly govern the handling of patient information.
The core principle involves a central server sending a global model to various participating healthcare institutions. Each institution then trains this model on its local, private dataset. Only the updated model parameters, not the raw data, are sent back to the central server. This iterative process allows the global model to learn from a vast, diverse dataset without ever directly accessing sensitive patient records.
The Challenge of Data Silos
- Regulatory Hurdles: Strict regulations like HIPAA often prevent healthcare organizations from sharing patient data, leading to isolated datasets.
- Data Heterogeneity: Different institutions may have varying data formats, collection methods, and patient demographics, making centralized aggregation difficult.
- Privacy Concerns: Even with de-identification, the risk of re-identification in aggregated datasets remains a significant barrier to collaborative research.
By keeping data localized, federated learning directly addresses these challenges, fostering collaboration while upholding the highest standards of data privacy. This decentralized training methodology is crucial for unlocking the full potential of AI in healthcare, enabling the development of more robust and generalizable models.
Ultimately, federated learning offers a pragmatic solution to the inherent tension between the need for large datasets to train effective AI models and the critical requirement to protect sensitive patient information. Its distributed nature ensures that data never leaves its secure environment, providing a strong foundation for privacy-preserving AI research.
Architectural Designs for Enhanced Privacy
The effectiveness of federated learning in reducing data privacy risks hinges significantly on its architectural design. Different designs offer varying levels of privacy protection, computational efficiency, and communication overhead. Understanding these distinctions is crucial for implementing federated learning responsibly in U.S. healthcare AI research.
Two primary architectural designs dominate the federated learning landscape: horizontal federated learning and vertical federated learning. Each is suited for different data distribution scenarios and offers unique privacy benefits, especially when augmented with additional privacy-enhancing technologies.
Horizontal Federated Learning (HFL)
HFL is applicable when datasets share the same feature space but differ in their sample IDs. This is common in healthcare where multiple hospitals might collect similar types of patient data (e.g., electronic health records) but from different patient populations. In HFL, each participant trains a local model on its unique set of patient data, and then only model updates are shared and aggregated by a central server.
- Shared Feature Space: All participants have data with similar attributes, such as demographic information, diagnoses, and treatment plans.
- Aggregated Model Updates: Only the learned parameters, not raw data, are transmitted, significantly reducing exposure risk.
- Scalability: Can involve a large number of participants, enabling the training of highly generalizable models across diverse patient populations.
Vertical Federated Learning (VFL)
VFL is employed when datasets share the same sample IDs but differ in their feature space. An example in healthcare would be a hospital and a pharmaceutical company having data on the same patients, but the hospital has clinical records while the pharmaceutical company has drug trial data. VFL allows these entities to collaboratively train a model without directly sharing their distinct feature sets.
In VFL, a secure multi-party computation protocol is often used to align the common sample IDs and perform calculations without exposing individual features. This is a more complex setup but offers unparalleled privacy for vertically partitioned data.
Both HFL and VFL can be further strengthened with techniques like differential privacy and secure aggregation, which add layers of protection to the model updates themselves, making re-identification even more challenging. The choice between these architectures depends on the specific data distribution and the privacy requirements of the collaborating healthcare entities.
The Role of Differential Privacy and Secure Aggregation
While federated learning inherently provides a degree of privacy by keeping raw data decentralized, its privacy guarantees can be significantly bolstered through the integration of advanced privacy-enhancing technologies. Differential privacy and secure aggregation are two such techniques that are particularly relevant for U.S. healthcare AI research, aiming to achieve that crucial 20% reduction in data privacy risks.
These methods act as additional safeguards, protecting against potential privacy breaches even from the shared model updates. Their combined application creates a robust framework for secure collaborative AI development.
Differential Privacy (DP)
Differential privacy is a rigorous mathematical framework that quantifies and limits the information leakage about individual data points from a dataset. In the context of federated learning, DP involves adding a carefully calibrated amount of random noise to the model updates before they are sent to the central server. This noise makes it statistically difficult for an adversary to infer details about any single individual’s data from the aggregated model.
- Quantifiable Privacy Guarantees: DP provides a strong, mathematically provable guarantee of privacy, allowing for a precise trade-off between privacy and model utility.
- Protection Against Membership Inference: It makes it challenging to determine if a specific individual’s data was included in the training set.
- Mitigation of Reconstruction Attacks: DP helps prevent attackers from reconstructing original data points from the shared model parameters.
Secure Aggregation (SA)
Secure aggregation protocols ensure that the central server, or any single participant, cannot learn the individual model updates from any single client. Instead, the server only receives the sum or average of all client updates. This is achieved through cryptographic techniques where clients encrypt their updates in such a way that only their aggregate can be decrypted by the server.
SA is particularly effective in preventing the central server from identifying which specific client contributed which model update, further enhancing the privacy of individual participants. When combined, differential privacy and secure aggregation create a formidable defense against various privacy attacks, making federated learning a much safer option for sensitive healthcare data.
By carefully implementing these techniques, federated learning architectures can provide a strong foundation for conducting AI research in healthcare that is both powerful and privacy-preserving, addressing the critical need for secure data handling.
Case Studies: Federated Learning in U.S. Healthcare
The theoretical benefits of federated learning are increasingly being realized through practical applications within the U.S. healthcare system. Several pioneering initiatives and research projects are demonstrating how these architectures can effectively reduce data privacy risks while still advancing critical AI research, often exceeding the targeted 20% reduction in risk exposure.
These real-world examples highlight the versatility and impact of federated learning, especially in areas where data sharing has traditionally been a significant hurdle.
Collaborative Cancer Research
One notable example involves a consortium of U.S. cancer centers using federated learning to train AI models for improved tumor detection and prognosis. Instead of pooling sensitive patient scans and clinical records, each center trains a local model on its own data. The aggregated model learns from the collective experience of all centers, leading to more accurate and generalizable diagnostic tools.
This approach has allowed researchers to leverage a much larger and more diverse dataset than would be possible with traditional methods, all while ensuring that individual patient data never leaves the confines of the originating institution. The privacy benefits here are immense, enabling breakthroughs in cancer research that were previously stymied by data sharing restrictions.
Predictive Analytics for Disease Outbreaks
Another compelling case involves using federated learning for early detection and prediction of infectious disease outbreaks. Various healthcare providers, from hospitals to public health agencies, can collaboratively train models on localized patient data (e.g., symptom reporting, lab results) to identify emerging patterns without sharing individual patient records.
This allows for a more rapid and comprehensive response to public health crises, as AI models can learn from a broader geographic and demographic spectrum of data without compromising patient privacy. The ability to quickly adapt and refine predictive models in a privacy-preserving manner is invaluable for public health initiatives.
These case studies underscore the transformative potential of federated learning in U.S. healthcare. They illustrate how innovative architectural designs, coupled with privacy-enhancing techniques, are not just theoretical constructs but practical solutions actively shaping the future of medical AI research while rigorously protecting patient confidentiality.
Challenges and Considerations for Implementation
While federated learning offers significant advantages for data privacy in U.S. healthcare AI research, its implementation is not without challenges. These considerations span technical, ethical, and regulatory domains, requiring careful planning and robust solutions to ensure successful and secure deployment. Addressing these aspects is crucial for achieving the desired privacy benefits.
Navigating these complexities is essential to fully realize the potential of federated learning in a sensitive field like healthcare.
Technical Hurdles
- Data Heterogeneity: Despite its benefits, differences in data quality, format, and distribution across healthcare institutions can still impact model performance and convergence.
- Communication Overhead: Frequent communication between clients and the central server to exchange model updates can be computationally intensive, especially with a large number of participants.
- System Heterogeneity: Participating devices or institutions may have varying computational capabilities and network bandwidths, leading to imbalances in training time and resource utilization.
Ethical and Regulatory Landscape
Beyond technicalities, the ethical implications of AI in healthcare, even with privacy-preserving techniques, remain a critical area of discussion. Ensuring fairness, accountability, and transparency in federated models is paramount. Furthermore, while federated learning addresses many HIPAA concerns, its exact compliance mechanisms and interpretations are still evolving.
Organizations must also consider the potential for adversarial attacks, where malicious actors might attempt to infer sensitive information from the shared model updates, even with differential privacy and secure aggregation in place. Continuous research and development are needed to strengthen these defenses.
Successfully implementing federated learning in healthcare requires a multi-faceted approach, combining advanced technical solutions with a keen awareness of ethical responsibilities and a proactive engagement with evolving regulatory frameworks. This holistic perspective is key to maximizing its benefits while minimizing associated risks.
Future Outlook and Emerging Trends
The landscape of federated learning in U.S. healthcare AI research is dynamic, with continuous advancements and emerging trends shaping its future. As the technology matures, we can expect even more sophisticated architectural designs and privacy-enhancing techniques that further solidify its role as a cornerstone of secure medical AI development. The quest for greater privacy and utility is ongoing.
These developments promise to expand the applicability and impact of federated learning across a wider range of healthcare scenarios.
Advanced Privacy-Preserving Techniques
Research is actively exploring the integration of homomorphic encryption, which allows computations to be performed on encrypted data without decrypting it first. While computationally intensive, combining this with federated learning could offer unparalleled privacy guarantees, potentially exceeding current benchmarks for risk reduction.
Another area of focus is the development of more robust adversarial attack detection and defense mechanisms specifically tailored for federated environments. As AI models become more complex, so do the methods used to try and extract sensitive information, necessitating continuous innovation in security.
Decentralized Federated Learning
- Blockchain Integration: Exploring the use of blockchain for decentralized coordination and secure logging of model updates, potentially eliminating the need for a central server.
- Peer-to-Peer Networks: Developing architectures where clients directly exchange model updates with each other, rather than through a central aggregator, further enhancing decentralization and resilience.
- Swarm Learning: An emerging variant where models are trained collaboratively on edge devices without a central coordinator, offering extreme data locality and privacy.
The future of federated learning in healthcare is bright, promising a future where cutting-edge AI models can be developed and deployed without ever compromising the sanctity of patient data. These evolving trends underscore a commitment to innovation that prioritizes both technological advancement and ethical responsibility, aiming to set new standards for data privacy in AI research.
| Key Aspect | Description |
|---|---|
| Data Decentralization | Raw patient data remains local, never shared directly. |
| Privacy Enhancements | Differential privacy and secure aggregation protect model updates. |
| Architectural Flexibility | Horizontal and vertical FL designs adapt to diverse data structures. |
| U.S. Healthcare Impact | Enables collaborative AI research while adhering to strict regulations. |
Frequently Asked Questions about Federated Learning and Healthcare Privacy
Federated learning trains AI models on decentralized datasets. Instead of sharing raw patient data, only model updates are exchanged, keeping sensitive information localized within each healthcare institution. This significantly reduces the risk of data exposure and enhances privacy.
Federated learning architectures, especially when combined with techniques like differential privacy, are estimated to reduce data privacy risks in U.S. healthcare AI research by 20% or more. This is achieved by preventing direct data sharing and obscuring individual contributions.
The main types are Horizontal Federated Learning (HFL), for datasets with similar features but different samples, and Vertical Federated Learning (VFL), for datasets with common samples but different features. Each is suited for specific data distribution scenarios.
While federated learning significantly enhances privacy, no system can guarantee 100% absolute privacy. However, combining it with techniques like differential privacy and secure aggregation provides robust protection against many common privacy attacks, making it highly secure for healthcare.
By keeping raw Protected Health Information (PHI) within the originating institution, federated learning inherently aligns with HIPAA’s core principle of data minimization and access control. Only aggregated, non-identifiable model updates are shared, reducing the scope of HIPAA-covered data transfer.
Conclusion
The exploration of federated learning architectures reveals a powerful and necessary evolution in how AI research is conducted, especially within the U.S. healthcare sector. By enabling collaborative model training without compromising the sanctity of patient data, these designs offer a robust solution to the persistent challenge of data privacy. The integration of advanced techniques like differential privacy and secure aggregation further fortifies these systems, demonstrably reducing privacy risks. As AI continues to transform medicine, federated learning stands as a critical enabler, fostering innovation while upholding the ethical imperative to protect sensitive health information, paving the way for a future where medical breakthroughs and patient trust coexist harmoniously.





